
Welcome to The Business Ops Blog
Here, you’ll find articles on operations, execution, and the systems behind scale. I use this space to break down the bottlenecks, weak handoffs, and structural problems that shape how companies actually run.
Don’t See What You’re looking For Yet? Send your request here and I’ll add it to the queue.

Stop Calling It Scrappy: Operational Chaos Has a Valuation Cost
This article breaks down why operational chaos is not just an internal startup problem, but an investor risk. It explains how early-stage governance helps founders prove their company can scale predictably without depending on founder rescue, messy reporting, or constant fire drills.

The Operating Layer You Need Before You Hire
A VA-ready business needs more than a growing workload; it needs a basic operating structure that allows someone else to run repeatable work without becoming dependent on the founder’s brain. This article walks through the task audits, client journey mapping, SOPs, and decision rights needed to turn vague “help” into clean ownership.

How One Broken Workflow Created a Full Day of Lost Revenue Every Week
What looked like a workload problem was actually a workflow problem. This article breaks down how one broken process created rework, trapped capacity, and lost billable time, and how redesigning the flow of work fixed it.

How Operators Can Find Hidden Workflow Risk Before It Spreads
Part 2 translates the Finnair lesson into a practical diagnostic for operators. It shows how to find the small workflow step quietly creating rework, delays, and downstream customer problems before it turns into a larger structural issue.

The €50 Part That Grounded an Airline
A low-cost seat-cover issue grounded 8 Finnair Airbus A321s, canceled about 70 flights, and disrupted roughly 11,000 customers. The real problem wasn’t the part. It was the weak upstream process around it, and every operator should recognize the pattern.

Why Busy Teams Still Fall Behind
Many teams feel maxed out long before they are actually at capacity. This article breaks down how rework, waiting, and broken handoffs create the illusion of overload and what operators should look at before adding headcount.

The Startup Onboarding Playbook
Weak onboarding is rarely just an HR issue. This article explains how founders can treat onboarding as an operational system and build a clearer, more predictable ramp.

When Revenue Runs on Rented Rails
This article uses the LTK backlash to examine a broader business problem: what happens when a company outsources a critical revenue function to infrastructure it does not control.

Your Hiring Process Is Either Protecting Runway or Burning It
A polished resume and strong interview do not prove someone can do the job. This article shows founders how to reduce false positives with evidence-based hiring methods and a structured onboarding process that catches issues early.

SaaS Sprawl Isn’t a Budget Problem
SaaS sprawl doesn’t happen because founders overspend. It happens because subscriptions become unowned, renewals happen by default, and tools outlive their purpose. This article breaks down the control pattern that stops drift and keeps your stack lean without constant attention.

What Block Actually Changed So AI Could Move Real Work
Block’s AI story isn’t about faster code. It’s about how they rebuilt structure, standards, and system-connected automation so AI could move real work without creating noise.

How to Stop Paying for the Same Work Twice
Part 3 introduces the Capacity Recovery Playbook: a practical guide to using DMAIC to strip rework, waiting, and friction out of stabilized workflows. If execution feels heavy, this is how you recover hours without adding headcount.

From Theory to Everyday Execution: The Operator’s Playbook (Part 2)
Part 2 moves past industry theory and delivers the Execution Control Blueprint—a practical, step-by-step playbook for your own business. It shows you exactly how to install the foundational controls needed to stop preventable rework and stabilize your workflows before you attempt to optimize them.

From Signed to Live: Building a Repeatable Delivery Engine
Booked ARR isn’t real until customers are live. If your implementation queue is bulging, you’re not scaling revenue, you’re scaling WIP. Here’s how to install the controls that turn onboarding into predictable execution.

IRROPS Recovery: The Operating System That Keeps a Bad Day From Becoming a Bad Week
Disruption is inevitable. Multi-day operational meltdowns usually aren’t. This article lays out the minimum recovery operating system that turns IRROPS from heroics into repeatable execution: clear decision rights, synchronized communications, feasibility checks, station-level guardrails, and a rhythm that produces decisions instead of debate.

Part 2: The Series B Playbook
Series B is where execution becomes the product. This guide lays out a 60-day install to make launches repeatable, convert failures into permanent system upgrades, and give leadership a clear view of reality before reliability, margin, and trust break.

Investors Fund Deployment, Not Just Ideas
Investors aren’t underwriting novelty at Series B. They’re underwriting your ability to deploy reliably, recover fast, and prevent repeat failures through a real operating system: a repeatable deployment engine, clear ownership, and governance that stops rework from compounding.
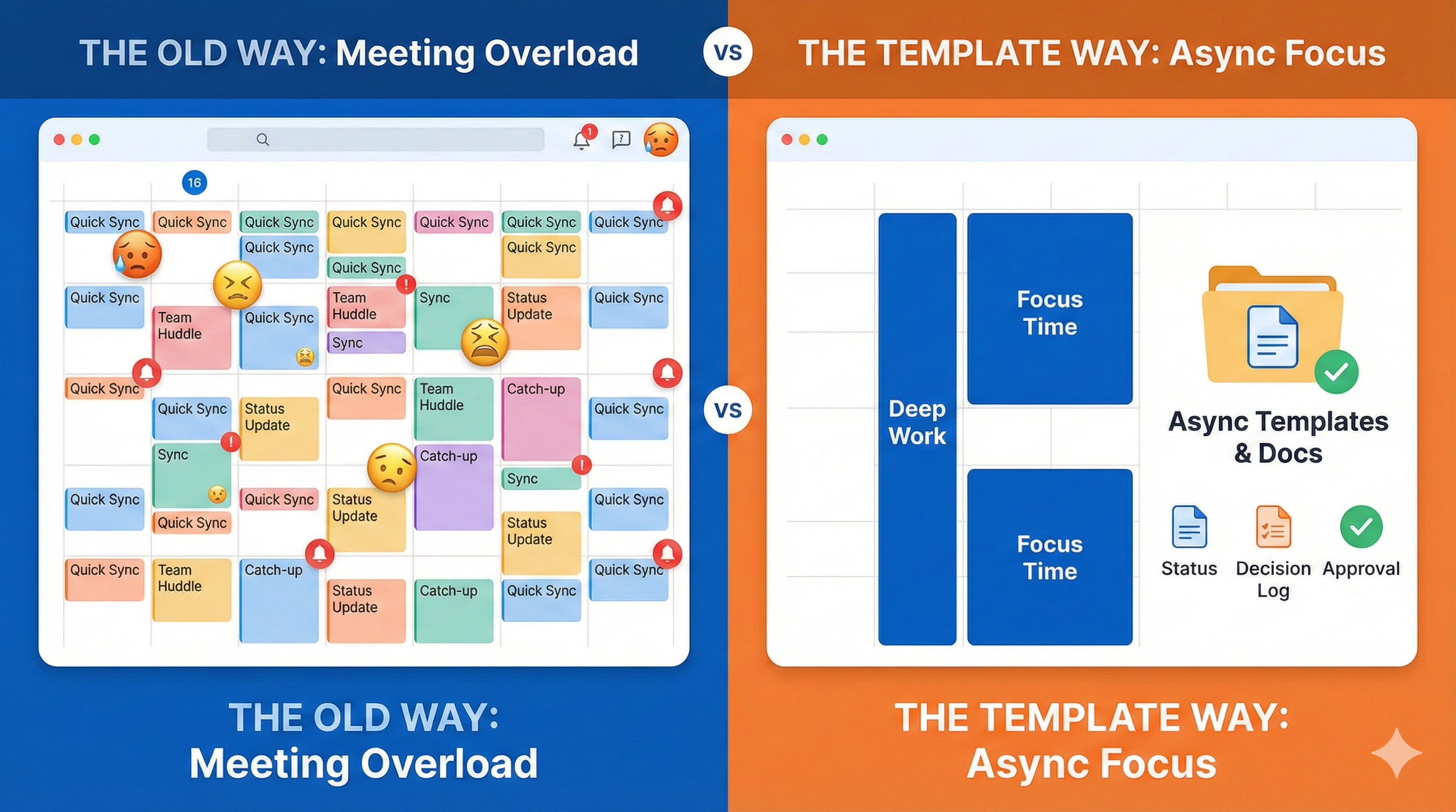
Part 2: The Templates (Copy, Paste, Run)
Most startups don’t have a meeting problem. They have a system problem, so meetings become the place where work, context, and decisions live. This template pack gives you the exact docs to move updates async, make approvals flow without calls, and force every meeting to produce a trackable receipt.

The Meeting OS: How To Cut Meetings Without Slowing Decisions
Meeting overload usually isn’t a time management problem. It’s an operating system problem. This 14-day plan shows how to convert update meetings into async templates, replace approvals with decision rights and intake standards, and keep only three recurring meetings that always produce a receipt.

Your First Hiring Wave Is Where Your Time Goes To Die
Learn how to move from reactive firefighting to intentional design with a 30-day hiring sprint designed to buy back founder capacity and protect your runway. This case study breaks down how to replace operational chaos with a repeatable, minimum viable hiring system.